


Existe mucha teoría sobre qué es un dato personal. En este artículo queremos responder una pregunta más concreta: ¿En la práctica que es un dato personal?
Porque al final, el cumplimiento de las leyes de protección de datos depende justamente de eso: saber cuándo estamos tratando datos personales y cuándo no.
No existe una definición universal
Puede parecer sorprendente, pero no existe una definición exactamente igual en todas las leyes de protección de datos.
Esto ocurre porque los datos son una representación de la realidad, y lo que puede identificar a una persona depende muchas veces del contexto.
Aun así, casi todas las normativas coinciden en un punto central: Un dato personal es información que dice algo sobre una persona.
El debate aparece cuando intentamos responder otra pregunta:
¿cuándo un dato se refiere a una persona? La respuesta cambia según la legislación.
Qué dice la nueva ley chilena
En Chile, la definición se actualizará con la entrada en vigencia de la Ley 21.719, que establece:
“Dato personal: cualquier información vinculada o referida a una persona natural identificada o identificable.
Se considerará identificable toda persona cuya identidad pueda determinarse, directa o indirectamente, en particular mediante uno o más identificadores, tales como el nombre,
el número de cédula de identidad, el análisis de elementos propios de la identidad física, fisiológica, genética, psíquica, económica, cultural o social de dicha persona.
Para determinar si una persona es identificable deberán considerarse todos los medios y factores objetivos que razonablemente se podrían usar para dicha identificación en el momento del tratamiento”
Analicemos la definición por partes
Si analizamos los componentes de esta definición:
Se refiere a personas naturales: Esto excluye a personas jurídicas, y considera a todas las personas naturales. Muchas organizaciones consideran sólo a los clientes como titulares de datos, con esto queda claro que esto no es correcto, debe considerar a toda persona natural. Ojo, no es sólo a los clientes, es a cualquier persona.
Información vinculada o referida: Es cualquier información, no lo acota a algún tipo de información (sólo establece categorías, que analizaremos en otro artículo) que se pueda vincular a una persona natural. Y lo que viene es clave:
Persona identificada o identificable: La ley habla extensamente de esto, e indica que no sólo es la información que se puede asociar directamente a una persona, sino que también su identidad pueda determinarse indirectamente. Esto no es tan obvio, ya que los datos son contextuales y los datos requeridos para identificar a alguien van a depender de ese contexto. Pero la ley si expresa que deben considerarse todos los medios objetivos que razonablemente se podrían usar para dicha identificación. Y aquí aparece el factor que es imprescindible en el mundo de los datos: el contexto.
Un ejemplo de la importancia del contexto
Es evidente que nombre y RUT son datos personales. Pero veamos otro caso, que se muestra en esta imagen:

No se mencionó el nombre ni el RUT.
Pero todas las personas presentes saben exactamente quién es.
Para quienes están en esa sala, la persona es perfectamente identificable, porque vieron a la persona. En cambio, alguien que no está ahí no podría identificarla.
Este ejemplo muestra que si los datos son identificables o no depende del contexto en el que se usan, o en que se realiza el tratamiento. O dicho de otro modo, de los datos adicionales que hay disponibles para poder saber a qué persona están referidos los datos.
Veamos un caso real en Chile
Cuando apareció el primer caso de COVID en Chile, muchos medios informaron que era: un hombre que viajó de Santiago a Talca, su profesión, dónde trabajaba, y otra información adicional. Nunca dijeron su nombre.
Pero entregaron suficientes antecedentes para que muchas personas supieran quién era.
Eso demuestra que incluso sin nombrar a alguien, puede ser identificable.
¿Qué es PII? ¿es lo mismo que dato personal?
En la literatura —especialmente estadounidenses— aparece el concepto PII (Personally Identifiable Information) frecuentemente.
Este concepto no es exactamente igual al de dato personal.
El PII suele referirse al dato que identifica directamente a una persona, por ejemplo:
número de seguridad social
RUT
número de pasaporte
Es decir, el identificador.
En cambio, en la legislación chilena (y también en el GDPR europeo), el concepto es más amplio.
Un dato personal puede ser cualquier información sobre una persona identificada.
Por ejemplo:
“Pedro tiene una discapacidad.”
La discapacidad por sí sola no identifica a alguien.
Pero si sabemos que la discapacidad es una característica de Pedro, entonces pasa a ser dato personal (y sensible).
Veámoslo con un ejemplo práctico
Entonces, un ejemplo práctico (con datos ficticios):
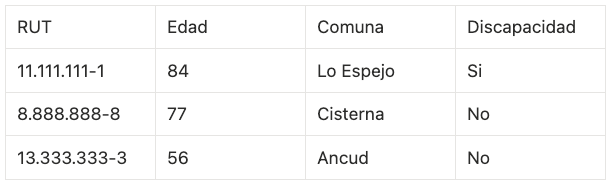
En esta tabla:
El RUT es el identificador (PII).
Ese identificador hace que todos los demás campos se conviertan en datos personales.
Porque ahora sabemos exactamente de quién es la edad, la comuna y la condición de discapacidad (y este último es un dato personal sensible)
Entonces, cuando estés en presencia de datos personales debes si o si cumplir la ley vigente y debes buscar disminuir el riesgo (para el titular y para la organización)
Una de las formas más efectivas de disminuir el riesgo es EVITANDO usar datos personales. Para ello, es imprescindible preguntarnos la finalidad del uso de dato personal. Si el objetivo es análisis estadístico, una buena manera de bajar el riesgo es eliminar el identificador.
Por ejemplo, borrar la columna RUT.
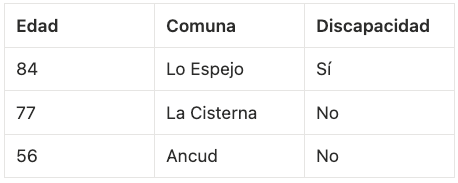
Esto reduce el riesgo de identificar a las personas.
Pero el riesgo disminuye aún más (incluso desaparece) si nunca se recolecta el identificador (en este caso el RUT). Entonces, si no se requiere, es mejor no recolectarlo, y asi el riesgo disminuye desde el origen.
Entonces, ¿qué no es dato personal?
Si el objetivo es reducir riesgos regulatorios, una buena práctica es trabajar con datos que no permitan identificar personas.
Dos formas comunes son:
Datos anónimos
Son datos que no pueden relacionarse con una persona específica.
Ejemplo:
“Persona de 84 años vive en Lo Espejo.”
Si no existe forma razonable de identificarla, no es un dato personal.
Datos agregados
Son datos que resultan de agrupar múltiples registros individuales.
Ejemplo:
“En Lo Espejo viven 40.000 personas mayores de 80 años.”
Este tipo de información suele aparecer en censos, estudios estadísticos o informes públicos.
Aquí no se puede identificar a nadie en particular.
La clave: pensar siempre en la identificabilidad
La principal enseñanza de este artículo es esta:
No importa solo el dato en sí. Importa si ese dato o un conjunto de datos permite identificar a una persona.
Por eso, al diseñar procesos o sistemas donde usaremos datos personales, siempre debemos preguntarnos:
¿necesito identificar a la persona?
¿podría trabajar con datos anonimizados?
¿puedo usar datos agregados?
Mientras menos datos se utilicen, menor será el riesgo que se puedan relacionar con una persona y por ende, el riesgo regulatorio y de privacidad.









