


Según el Art. 7 de la ley 21.719 (que modifica la ley 19.628), toda persona tiene derecho a solicitar la supresión de sus datos personales. Supongamos que estamos a 1 de diciembre de 2026, entra en vigencia la norma y uno de tus usuarios ejerce el derecho de supresión. ¿Cómo lo resolverías?
En organizaciones corporativas, realizar la eliminación de datos personales de un usuario no es trivial. Esto porque seguramente existen sistemas distribuidos, microservicios y múltiples fuentes de datos.
Nishant Bhajaria, autor de Data Privacy, en uno de sus cursos muestra en la siguiente imagen cómo los datos viajan tras ser recolectados
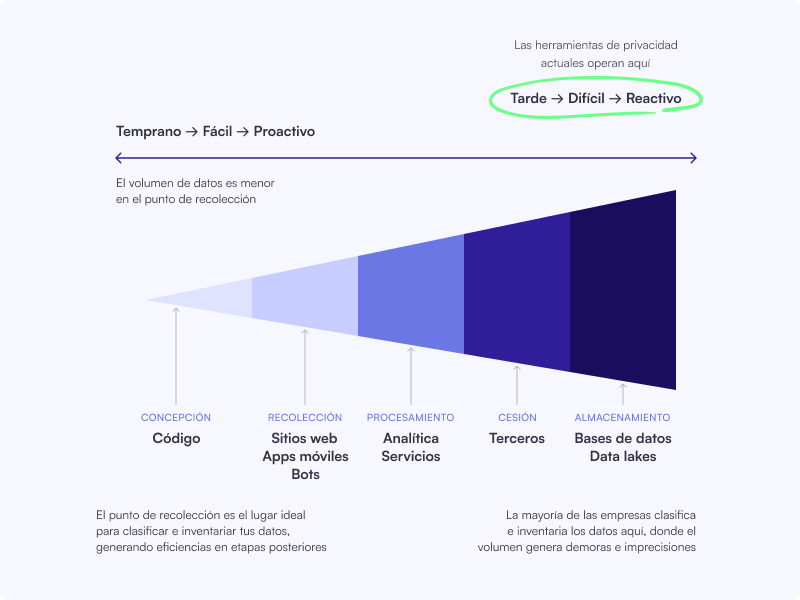
En ella se evidencia que la reactividad que tienen las organizaciones en la implementación de herramientas de privacidad les quita efectividad, cuando ya los datos recolectados han sido transferidos a diferentes sistemas: servicios de analítica, terceros, data lakes, etc.
Por lo tanto, eliminar ese dato que hoy podría estar almacenado en diferentes fuentes de información es un “cacho”, como diríamos en Chile, a un problema.
Podrías intentar resolverlo de forma manual, solicitando a cada área o Data Owner (responsable del dato) que ejecute la eliminación del usuario en sus sistemas y que te envíe la evidencia correspondiente.
Los equipos encargados tendrán mucho miedo de hacerlo. No hay nada más difícil que ejecutar un DELETE.
Estás de acuerdo en que esta opción no es escalable en el tiempo; generaría una carga operativa indeterminada a todos los equipos involucrados (pero sirve para que la organización aprenda cómo proceder).
Podrías entonces crear un (micro) servicio que tenga la conectividad y los usuarios con permisos necesarios para ir a cada base de datos y ejecute la operación DELETE directamente.
Desde un punto de vista de arquitectura de software estaríamos generando un acoplamiento indebido, ya que el resto de microservicios perderían control sobre las reglas de negocio que gobiernan sus propios datos. Además, no sólo encarece la mantención, sino que también incrementa el riesgo de errores.
¿Qué hacemos entonces? En este artículo revisaremos algunas definiciones más para entender mejor el problema de la eliminación y revisar una solución propuesta por Nishant B.
Qué significa realmente eliminar datos
Desde mi experiencia, existen dos mecanismos válidos que permiten cumplir con la exigencia de la Ley, cada uno con implicancias técnicas distintas:
1. Eliminación física o lógica
La eliminación física implica la destrucción definitiva de los datos. Es la forma más directa, pero no siempre es viable en sistemas complejos.
La eliminación lógica, en cambio, consiste en marcar los datos como eliminados (por ejemplo, mediante flags como is_deleted). Este enfoque es común en sistemas donde se requiere trazabilidad o recuperación. El problema es que, desde el punto de vista legal, esto por sí solo puede no ser suficiente. Por lo que se debe aplicar una técnica de anonimización para no caer en incumplimiento.
2. Anonimización
Según la ley, un dato anonimizado es aquel que no puede ser vinculado a una persona natural y es irreversible.
Esto implica que:
- No debe existir ninguna clave que permita reidentificar al usuario
- No deben quedar combinaciones de datos que permitan inferir la identidad
- No debe existir información auxiliar que permita reconstruir el vínculo
Por ejemplo:
- Remover el RUT pero dejar fecha de nacimiento, comuna y género puede permitir reidentificación
- El hashing simple puede ser reversible en la práctica. Es decir, aunque transformes un dato (como un RUT) en otro valor aparentemente irreconocible, alguien podría reconstruir el original probando combinaciones conocidas.
- Mantener tablas de correspondencia —es decir, listas que vinculan el dato original con su versión transformada— rompe completamente la anonimización, ya que permite volver directamente a la identidad de la persona.
Existen diferentes técnicas de anonimización; lo importante es reducir los riesgos de identificación.
La siguiente imagen resume cómo las diferentes técnicas de anonimización no son infalibles para mitigar todos los riesgos

Explicación de los Niveles de Riesgo:
Sí: la técnica no mitiga eficazmente el riesgo y requiere el uso combinado con otras técnicas para mejorar la protección.
A veces: la técnica puede mitigar el riesgo en ciertas circunstancias o hasta cierto grado. Es importante considerar el contexto específico en el que se aplicará la técnica.
No: la técnica es efectiva para mitigar el riesgo asociado, ofreciendo una protección robusta contra el tipo de riesgo especificado.
Si bien las técnicas de anonimización no son infalibles, puede haber casos en los que si cumplan con lo requerido en la ley. Tendremos más claridad cuando la agencia se pronuncie al respecto.
En muchos casos, técnicas como la anonimización o la eliminación lógica se utilizan para cumplir con este objetivo, siempre que los datos ya no permitan identificar a una persona.
Dónde deben eliminarse los datos
Los datos personales suelen estar distribuidos en múltiples lugares:
- Bases de datos relacionales y no relacionales
- Sistemas de archivos (documentos, imágenes, exportaciones)
- Sistemas de mensajería y logs
- Correos electrónicos
- Chats
- Sistemas de terceros
- Otros
Es tarea de la organización identificarlos y borrar en todos ellos.
Cuánto eliminar
El derecho de supresión no siempre implica borrar toda la información. En la práctica, existen al menos dos escenarios:
- Eliminación parcial: el usuario solicita eliminar ciertos atributos específicos.
- Eliminación total: se elimina toda la información asociada al titular.
Sin embargo, lo que efectivamente se puede eliminar no depende solo de la solicitud del usuario, sino también de las obligaciones legales y regulatorias de la organización. Por ejemplo, ciertos datos —como registros de deudas o información contable— pueden requerir ser conservados por ley.
Esto implica que los sistemas deben ser capaces de eliminar, considerando tanto la solicitud del titular como las restricciones legales aplicables.
Orden de eliminación
Los datos pueden reaparecer debido a replicación o sincronización. Por lo tanto, el orden recomendado es:
- Sistemas fuente
- Sistemas replicados o derivados
Este orden minimiza inconsistencias y evita la regeneración de datos eliminados. Importante considerar que muchas veces los sistemas fuente o sistemas replicados pueden ser terceros (proveedores)
Con estas definiciones entonces, vamos con el diseño principal del sistema de eliminación propuesto, esta idea está inspirada en el libro Data Privacy: A runbook for engineers de Nishant Bhajaria, en el capítulo 7.
Destroyer
El Destroyer en su concepción más básica es un servicio central que soporta la eliminación de datos personales de diferentes fuentes de información frente a una solicitud de supresión de un usuario. Esto se logra a través de la orquestación de servicios de eliminación de diferentes sistemas.
El Destroyer es un servicio encargado de:
- Orquestar la eliminación en múltiples sistemas
- Mantener trazabilidad del proceso
- Ejecutar validaciones previas
- Garantizar consistencia
No elimina datos directamente. Coordina a los sistemas que sí lo hacen.

Antes de eliminar cualquier dato, es obligatorio validar si existe una razón legal para mantenerlo. Esto incluye:
- Retenciones legales (productos activos)
- Obligaciones regulatorias (envío de información a instituciones)
- Procesos judiciales (Ley papito corazón)
Para esto se introduce un servicio especializado (Holden, en la imagen), que centraliza estas validaciones.
El flujo es simple:
- Si hay razón legal para mantenerlo → no se elimina
- Si no existe → se puede proceder
Este paso es crítico para evitar incumplimientos legales por eliminación indebida.
Una vez validado que el usuario no tiene retención legal, se debe dar inicio al mecanismo de eliminación.
Para ello, los dueños de servicios por sistema, quienes son responsables de la administración de las bases de datos que contienen los datos personales, deben registrar sus servicios de eliminación en conjunto con los datos personales a eliminar en el Destroyer.
Servicios de eliminación
Cada sistema debe crear 3 servicios que serán necesarios por el Destroyer para ejecutar la eliminación:
- GET_TEST_USER: Retorna un user_id para probar la eliminación. El usuario retornado debe tener los datos suficientes para probar el flujo de eliminación.
- Observación: luego de hacer pruebas, se debe considerar realizar “un-delete” los datos generados por el usuario.
- DELETE: El servicio principal que ejecuta la eliminación. Va desde la eliminación completa al uso de alguna técnica de anonimización.
- IS_DELETED: Determina si los datos de un usuario fueron eliminados o no.
El flujo de prueba debería ser:
- Generar un usuario de prueba GET_TEST_USER
- Verificar que no está eliminado IS_DELETED -> false
- Ejecutar la eliminación DELETE
- Confirmar que fue eliminado IS_DELETED -> true
Esto debe repetirse por cada sistema registrado en Destroyer, revisemos entonces cómo organizar la eliminación
Plan de eliminación
Cuando se recibe una solicitud de eliminación en Destroyer, el sistema debe generar un plan según lo que el usuario haya pedido. No es lo mismo una eliminación total que una parcial (por ejemplo, borrar solo el correo).
De ahí la importancia de contar con un buen contrato de registro de los sistemas en Destroyer (en este caso, “contrato” se refiere a una definición técnica de cómo funciona un sistema: qué datos maneja y cómo otros sistemas pueden interactuar con él)
Como mínimo, este contrato debe incluir:
- Qué datos personales almacena cada sistema
- Las URLs de los tres servicios definidos previamente
- El método de autenticación
- Qué sistemas son fuente y cuáles replican datos (puede haber varios sistemas replicando desde una misma fuente)
- Si la eliminación es síncrona o asíncrona (algunos sistemas no podrán eliminar en línea y responderán después)
- Si requiere aprobación manual
Con esta información, se construye el plan de eliminación.
Este plan consiste en ejecutar la eliminación de datos de forma ordenada por niveles, desde el nivel 0 hasta el nivel N:
- En el nivel 0 están los sistemas fuente (el origen de los datos)
- En el nivel 1 están los sistemas que replican datos del nivel 0 y, a su vez, alimentan a otros
- Y así sucesivamente hasta el nivel N
Este orden es importante para mantener la integridad de la información y evitar que los datos eliminados vuelvan a aparecer por procesos de replicación. Además, todos los sistemas que están en un mismo nivel pueden ejecutar la eliminación en paralelo, lo que hace el proceso más eficiente.
Antes de concluir este post, te muestro cómo imagino que se podría mostrar la ejecución de la eliminación de una solicitud de supresión por parte de un usuario
%2011.49.38%E2%80%AFa.m..png)
Todo lo anterior no solo permite ejecutar correctamente la eliminación de datos, sino también dejar evidencia trazable de qué se hizo, cuándo y en qué sistemas.
Esto es clave, porque ante una eventual fiscalización, tu organización debe ser capaz de demostrar cómo implementa el derecho de supresión en la práctica.
En ese contexto, la Agencia de Protección de Datos Personales probablemente quedaría sorprendida de obtener una auditoría de esa calidad de parte de tu organización.
Últimas palabras
El derecho de supresión es, en esencia, un problema de arquitectura. Obliga a responder preguntas complejas: dónde viven realmente los datos, cómo se propagan y cómo garantizar que se eliminen de forma efectiva.
Implementarlo correctamente requiere pensar en orquestación, consistencia distribuida y contratos entre sistemas.
En otras palabras, no es un requerimiento legal aislado, sino una oportunidad para diseñar sistemas más conscientes, controlados y responsables con los datos que gestionan.
La solución propuesta no siempre será viable de inmediato, pero marca un objetivo claro hacia dónde avanzar. Adoptarla, incluso de forma parcial o progresiva, ya implica un salto importante en la forma en que una organización entiende y gestiona sus datos y al derecho de supresión.








